
《地方数据治理与数字内容出口》一文中用到了关键词词频量化的方法。我将原始代码完善了一下,打包成如下project,仅供参考。
Content
0.info
author: @mengke25
repository: https://github.com/mengke25/policy_text_frenq
date: 2024-08-08
1. 项目简介
本项目用于处理原始的txt格式或docx格式的政策文件,提取关键词词频率,并进行可视化展示。
2. 项目结构
- 路径介绍
- pool: 存放原始的文本文件,应为
txt文件或docx文件 - script: 存放处理脚本与函数,目前只需要关注
s1_textclear.py - output: 存放处理结果,该结果中包括了文件名、关键词、词频、政策年份、发布政策的城市或省份
- files: 用于存放词典和去停用词列表,其中
stopwords.txt为去停用词列表,custom.txt为词典文件,可根据需要自行修改:- 停用词是指:在文本处理过程中,我们通常会将一些不重要的词语(如“的”、“是”、“了”等)去掉,这些词语对文本的分析没有太大的意义,因此可以将其视为停用词。
- 词典是指:在文本处理过程中,我们可能涉及到一些专业名词,如“数据跨境流动”、“数据开放共享”等,这些词语在文本以一个整体存在,如果不定义的话,
jieba包可能将其拆成多个词语,影响最终的结果。因此,我们可以将这些词语定义为词典,以便jieba包能够正确识别。
- requirements.txt: 存放项目所需的依赖包,可使用
pip install -r requirements.txt安装。 - readme.md: 项目说明文档,也即本文件
- pool: 存放原始的文本文件,应为
3. 脚本释义
s1_textclear.py脚本主要完成了从原始文本文件(txt)中提取信息、转换格式,并生成一个包含关键词统计结果的Excel文件的过程。具体来说,它分为几个主要步骤:
(1)准备阶段
a.输入和定义
- 输入的关键词列表:定义了需要搜索和统计的关键词。
- 文件路径:定义了基本路径、原始文件路径、输出路径、停用词和自定义词典的路径。
b.加载自定义词典和停用词
- 加载自定义词典:使用
jieba加载自定义词典以便于后续的分词处理。 - 加载停用词:从文件中读取停用词列表。
c.清理文本函数
clean_text函数:用于移除无效字符。extract_year_from_text函数:从文本中提取年份。extract_year_from_filename函数:从文件名中提取年份。
(2)脚本步骤
步骤一:txt文件转换为docx文件
- 遍历所有txt文件:检查目标文件夹中所有txt文件,并将其转换为docx文件。
- 清理内容:在转换过程中,使用
clean_text函数清理文本内容。 - 保存docx文件:将清理后的内容保存为docx文件,跳过已经存在的文件。
步骤二:分析docx文件并生成Excel文件
- 遍历所有docx文件:读取docx文件中的内容。
- 提取年份:从文件名或内容中提取政策年份。
- 先寻找题目中是否有年份,如果有的话定义其为年份
- 否则的话就进入文本中去遍历寻找
- 分词和停用词过滤:使用
jieba对内容进行分词,并过滤掉停用词。 - 统计关键词出现频次:计算每个关键词在文档中出现的频次。
步骤三:调用外部函数,定位城市和省份,并生成DataFrame
- 创建DataFrame:使用Pandas创建数据框架,并初始化
citycode和provcode列。 - 备份原始数据:备份
citycode和provcode列的原始值。 - 调用
citycode函数:更新数据框架中的citycode列。 - 判断地级市层面:检查
citycode是否发生变化,并标记地级市层面的政策。 - 调用
provcode函数:更新数据框架中的provcode列。 - 判断省份层面:检查
provcode是否发生变化,并标记省份层面的政策。
4. 运行方法
- 第一步,将原始的文本文件(txt)或docx文件放入
pool文件夹中。 - 第二步,运行
s1_textclear.py脚本,其中有两个参数要修改- 一是关键词(
s1_textclear.py第13行):keywords = ["数据跨境", "数据流动", "数据共享"] - 二是文件路径(
s1_textclear.py第18行):base_path = "D:\\py_proj\\policy_analyse"
- 一是关键词(
- 第三步,docx文件会被转换为txt文件,并保存在
output文件夹中。 - 第四步,运行
s1_textclear.py脚本,生成Excel文件。
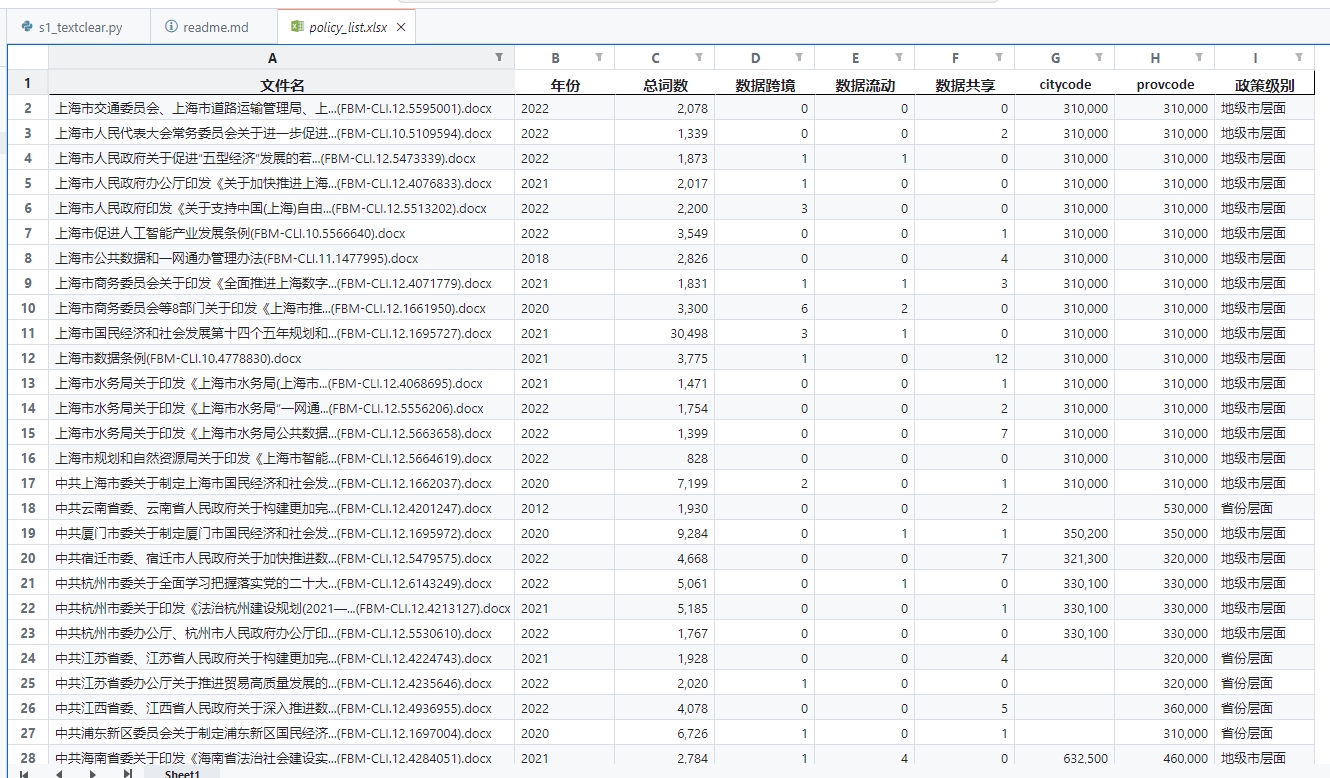
5. 结果展示
6. 项目部署
(1)将项目下载到本地
- 可以去项目地址打包下载
- 可以使用git clone命令下载:
git clone https://github.com/mengke25/policy_text_frenq.git - 或者邮箱私信我
(2)安装依赖
方法1:直接安装
最简单直接的方法,用win+r,键入cmd,打开命令行,输入以下命令:
pip install python-docx
pip install pandas
pip install numpy
pip install jieba
方法2:使用requirements.txt安装
用win+r,键入cmd,打开命令行,输入以下命令:
在cmd中安装需用到的packages
d:
cd d:\policy_text_frenq-main
# 这里 对于两类用户有两种选择
# 选择1:使用python安装,requirements.txt中的包
python -m pip install -r requirements.txt
# 选择2:如果是conda用户,安装requirements.txt中的包方式如下(附虚拟环境)
conda create -n env2 python=3.11 # 创建anaconda环境
conda activate env2 # 激活anaconda环境
python -m pip install -r requirements.txt
(3)安装完成后,运行脚本
这里详见 4. 运行方法
{kind=link}