
用于在python中调用open AI的API,处理xlsx表格中的自然语言文本。一个专门做dirty work的好帮手
0. project url
-
项目主页:proj_textOpenAI;
-
Github主页:@mengke25;
-
项目教程:guide video;
-
请喝咖啡:(●’◡’●)
{kind=link}
1. project简介
(1)概况
用于在excel中调用chatGPT、Claude等AI,帮忙进行自然语言处理,并输出相应的内容。它是一个专门做dirty work的RA
(2)主要功能
我们把自然语言放到excel的某一列,比如是一段文本 我们可以在promot中说‘请帮我提炼关键词’,‘请帮我总结’,‘请帮我翻译’,‘请判断是积极还是消极’,‘请帮我做相应的处理’ AI会根据我们输入的文本,给出相应的处理结果,并输出到excel的某一列
(为了提高运行速度,我将每个xlsx拆成了若干个,同时运行。)
(3)应用场景
- 文本分析:对文本进行分析,提取关键词,判断情感倾向等
- 文本处理:对文本进行清洗,去除无用信息,提取关键信息等
- 文本翻译:将文本翻译成另一种语言
- 文本分类:对文本进行分类,比如新闻、评论、微博等
- 文本生成:根据输入文本,生成相应的文本
- 文本推荐:根据用户的兴趣,推荐相关的文本
- 文本摘要:对文本进行摘要,生成简短的文本
- 文本风格迁移:将文本风格迁移到另一种风格
- 文献综述撰写:根据文献,生成综述
2.本地部署教程
(1)将项目下载到本地
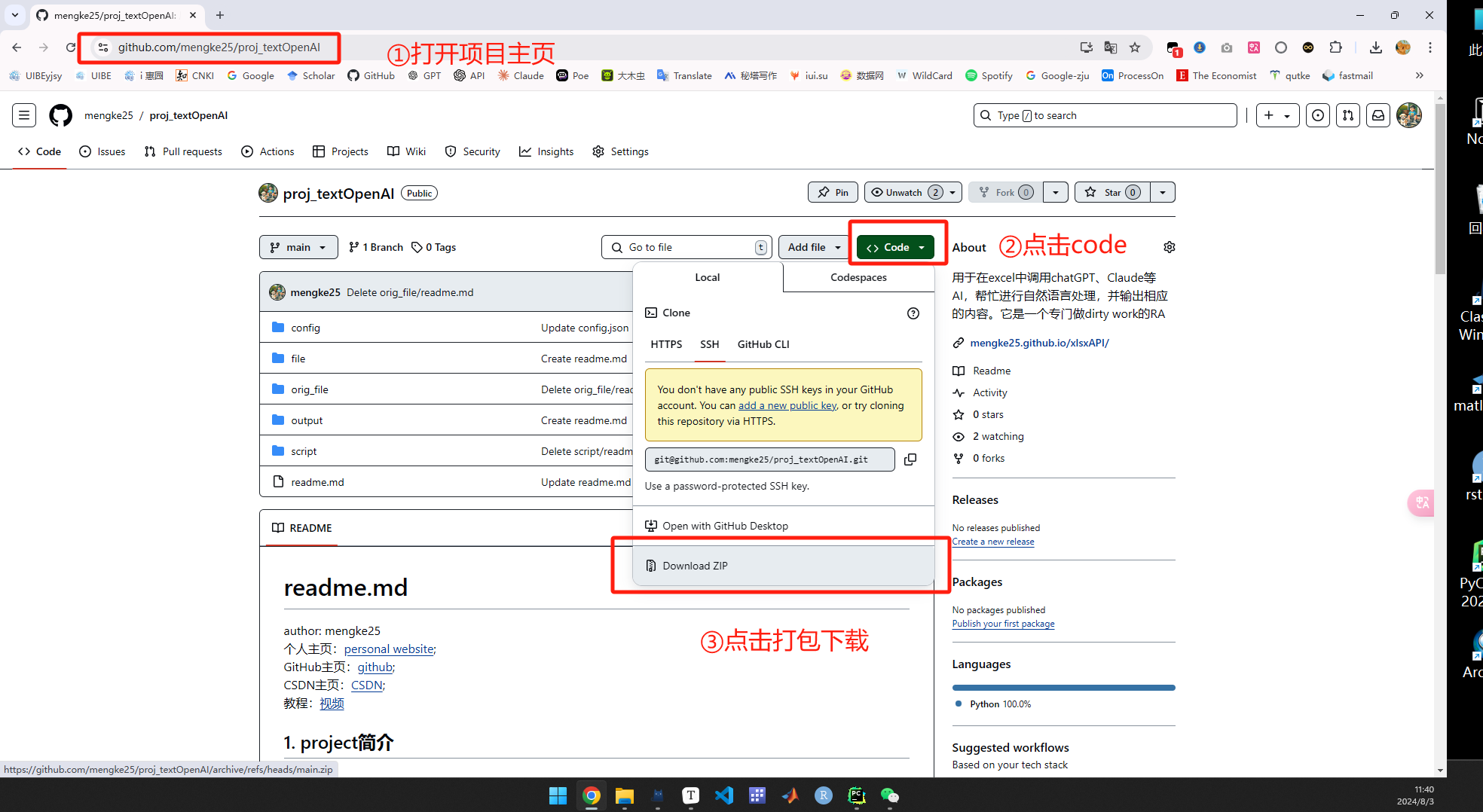
或者在cmd中可直接clone
d:
git clone https://github.com/mengke25/proj_textOpenAI.git
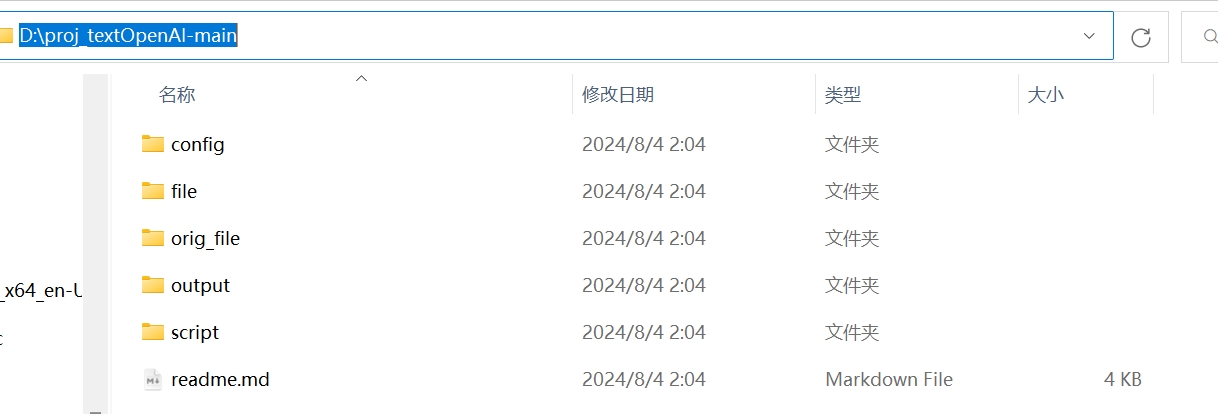
比如在这里,我直接将项目整体放在了D盘中
(2)安装依赖
在cmd中安装需用到的packages
# 首先,将路径切换到根目录下
d:
cd d:\proj_textOpenAI-main
# 选择1:使用python安装,requirements.txt中的包
python -m pip install -r requirements.txt
# 选择2:如果是conda用户,安装requirements.txt中的包方式如下(附虚拟环境)
conda create -n env2 python=3.11 # 创建anaconda环境
conda activate env2 # 激活anaconda环境
python -m pip install -r requirements.txt
下面我们就要进入正题了!
但在运行之前,还需要找到两个核心文件:
用编译器打开该项目的文件夹,此处我用vscode来演示
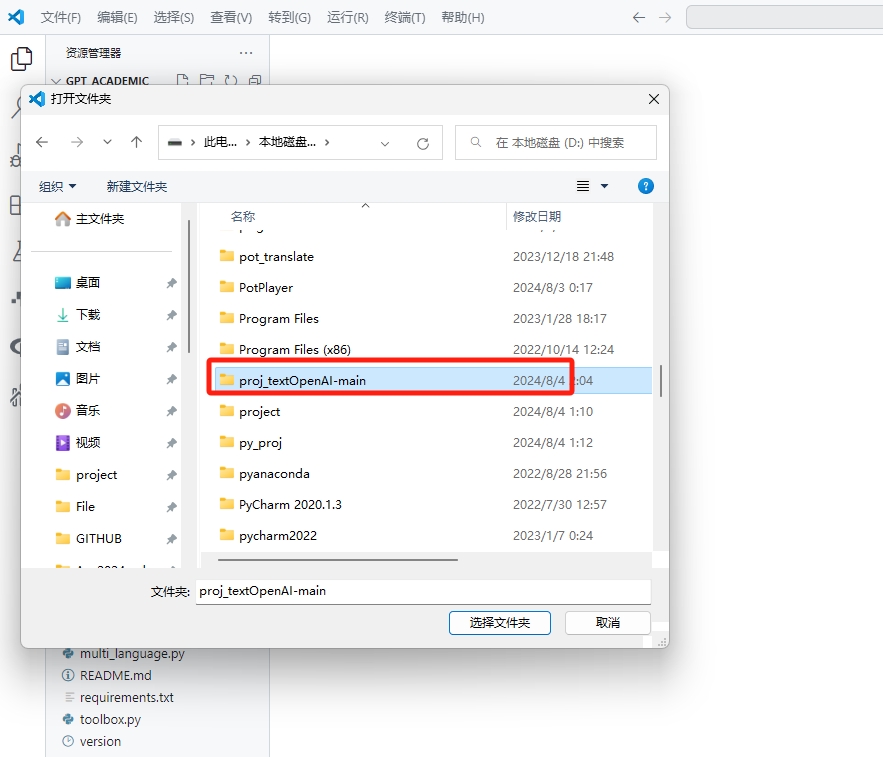
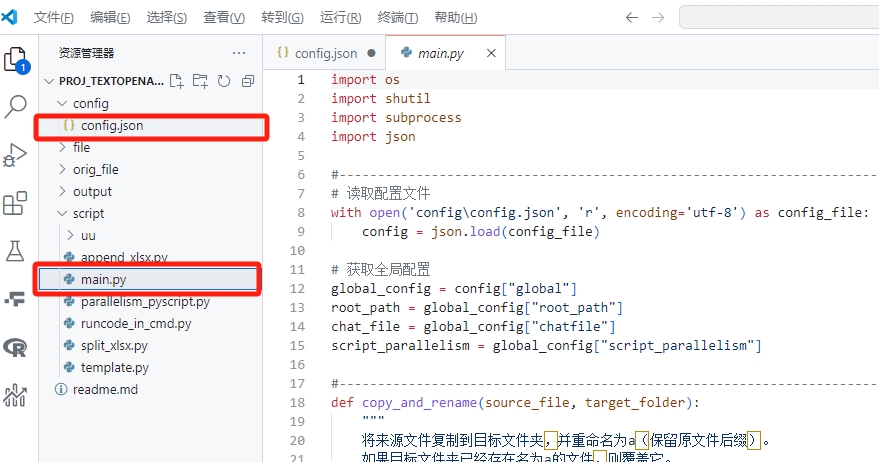
打开文件夹后,请找到config路径下的json文件,以及script路径下的main.py
这两个文件是本项目的核心文件
其中config.json中定义了宏变量,main.py则是主脚本
至此,本地部署已完成。下面我来介绍该如何使用。
3. 使用方法
使用方法非常简单,分两步——修改宏变量+运行主脚本
(1)step1:改宏变量
第一步,修改config路径下的json配置文件,prompt改成自己的需求,其中:
root_path: 项目路径,即本地路径,例如打包下载到D盘,那项目路径就应该是D:\\proj_textOpenAI-main,注意这里是双斜杠chatfile:待处理文件,也即要读取的文件apikey:是openai的api key,需要自己申请,也可以第三方(如柏拉图),或者直接某宝去购买apiurl:是openai的api url,若使用openai个人申请的API,空着即可model_name:是AI模型的名称,支持 “gpt-3.5-turbo”等,常见的模型有:- GPT-4, GPT-4-32k: 通用性很强,适用于各种复杂的自然语言处理任务。
- GPT-4-Turbo, GPT-4-Turbo-2024-04-09: 优化的版本,速度更快,费用可能更低。
- GPT-4-1106-preview, GPT-4-Turbo-preview, GPT-4-Vision-preview: 这些是预览版本,可能包含一些最新功能和改进。
- GPT-4o, GPT-4o-mini: 优化版本,关注特定性能提升,具体细节需要查看官方文档。
- Azure-GPT-4: Azure平台上的GPT-4,集成在Azure生态系统中,便于使用Azure的其他服务。
- GPT-3.5-Turbo, GPT-3.5-Turbo-1106, GPT-3.5-Turbo-16k: 通常比基础版GPT-3更快且更便宜,适合需要快速响应且较为复杂的任务。
- Azure-GPT-3.5: 相对于标准GPT-3.5,集成在Azure平台上,更方便使用Azure的服务。
- GLM-4, GLM-4v, GLM-3-Turbo: 由不同组织开发的模型,如GLM4、GLMv4等,适用于特定场景和任务,详细性能需参考相应的技术文档。
- 具体细节需查看发布方的文档,但通常是较高性能的模型,可能在某些特性上有独特的优势。
- 专注于对话生成任务,适合需要高质量交互的应用。
input_col:是输入文本所在的列,也即想输入给AI的列output_col:是输出结果所在的列,也即想让AI输出在excel的哪一列python_env:所使用的python环境,一般情况下应该是”base”script_parallelism:是脚本并行度,即运行几个脚本,一般设置为10,最多不超过30prompt_template:是AI的提示模板,可以自己修改system_message:是系统提示语,可以自己修改
一个示例:
{
"global": {
"root_path": "D:\\proj_textOpenAI-main",
"chatfile": "D:\\proj_textOpenAI-main\\orig_file\\targetfile.xlsx",
"apikey": "sk-aUF5e29*****************8f6SeLz",
"apiurl": "https://api.gptsapi.net/v1",
"model_name": "gpt-3.5-turbo",
"input_col": 4,
"output_col": 10,
"python_env": "env2",
"script_parallelism": 20,
"prompt_template": "请根据我输入给你的文本,帮我判断一下这段文本是否属于abc。",
"system_message": "你是一个帮助判断是否未规制的助手"
}
}
(2)step2:运行
第二步,修改好配置文件后,运行main.py。
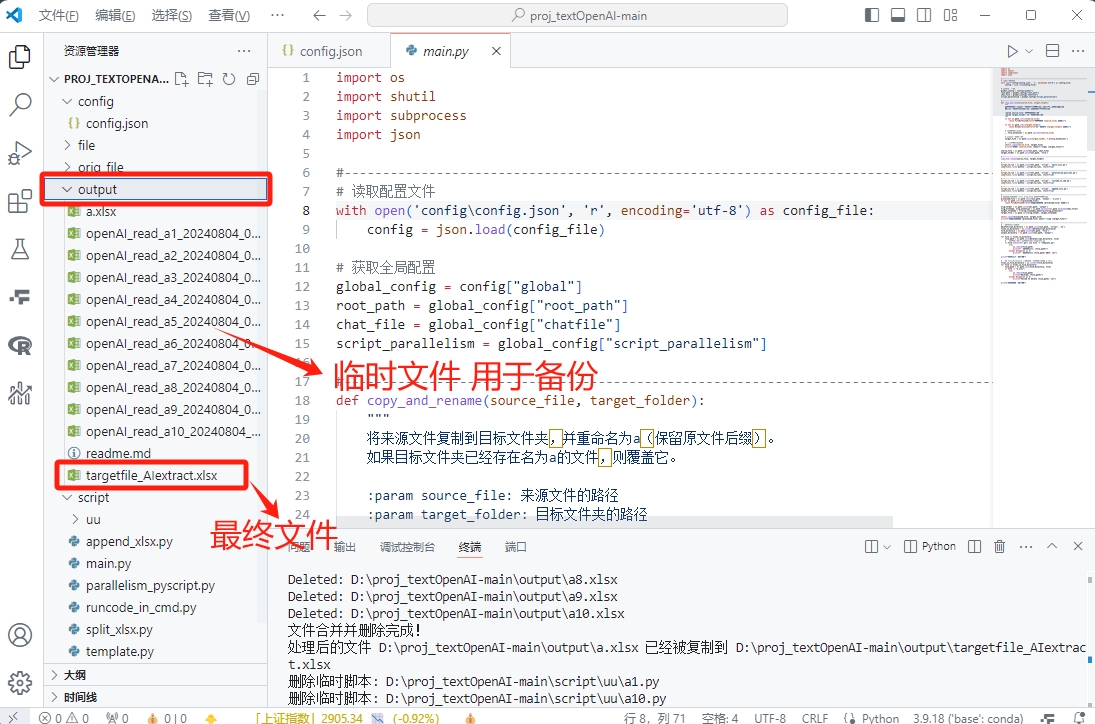
等运行完,去output文件夹将'****_AIextract.xlsx'找出来,即可。再生成最终文件的同时,还会生成若干个子文件,用于备份。如果不需要的话,可以直接删掉。
(3)补充
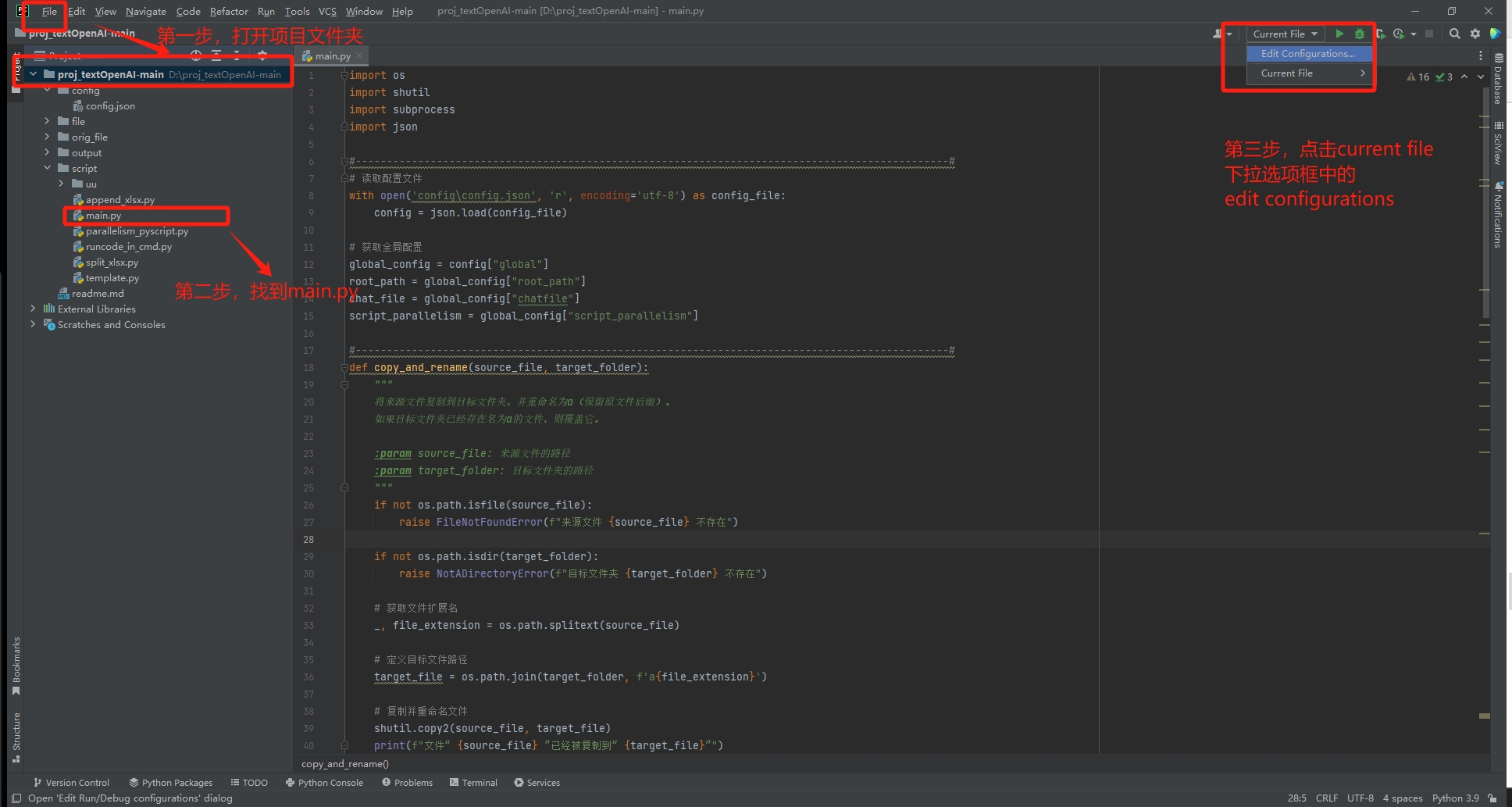
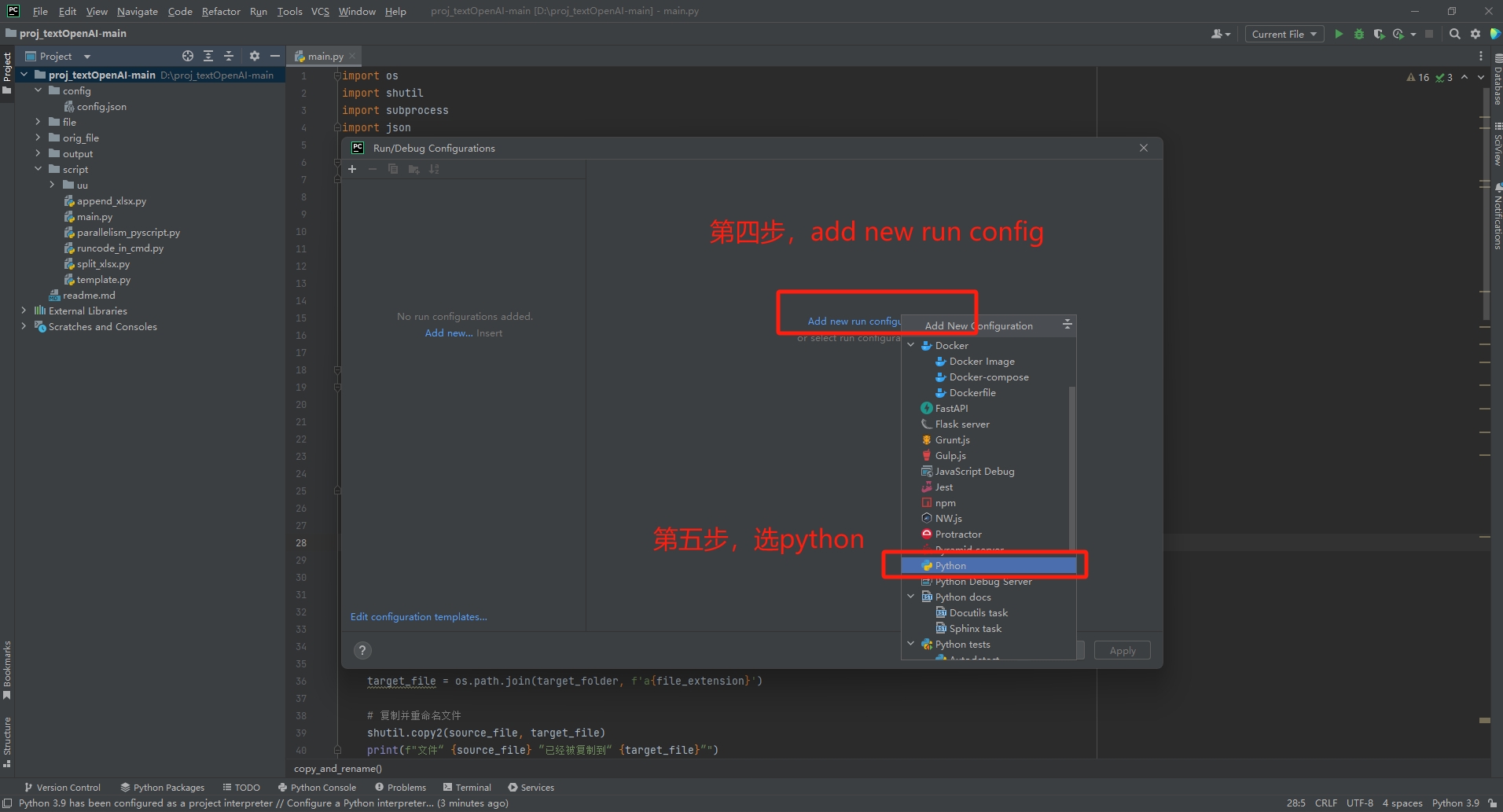
对于pycharm用户,可能会遇到找不到相对路径的问题,
此时需要您去配置run config
具体步骤如下
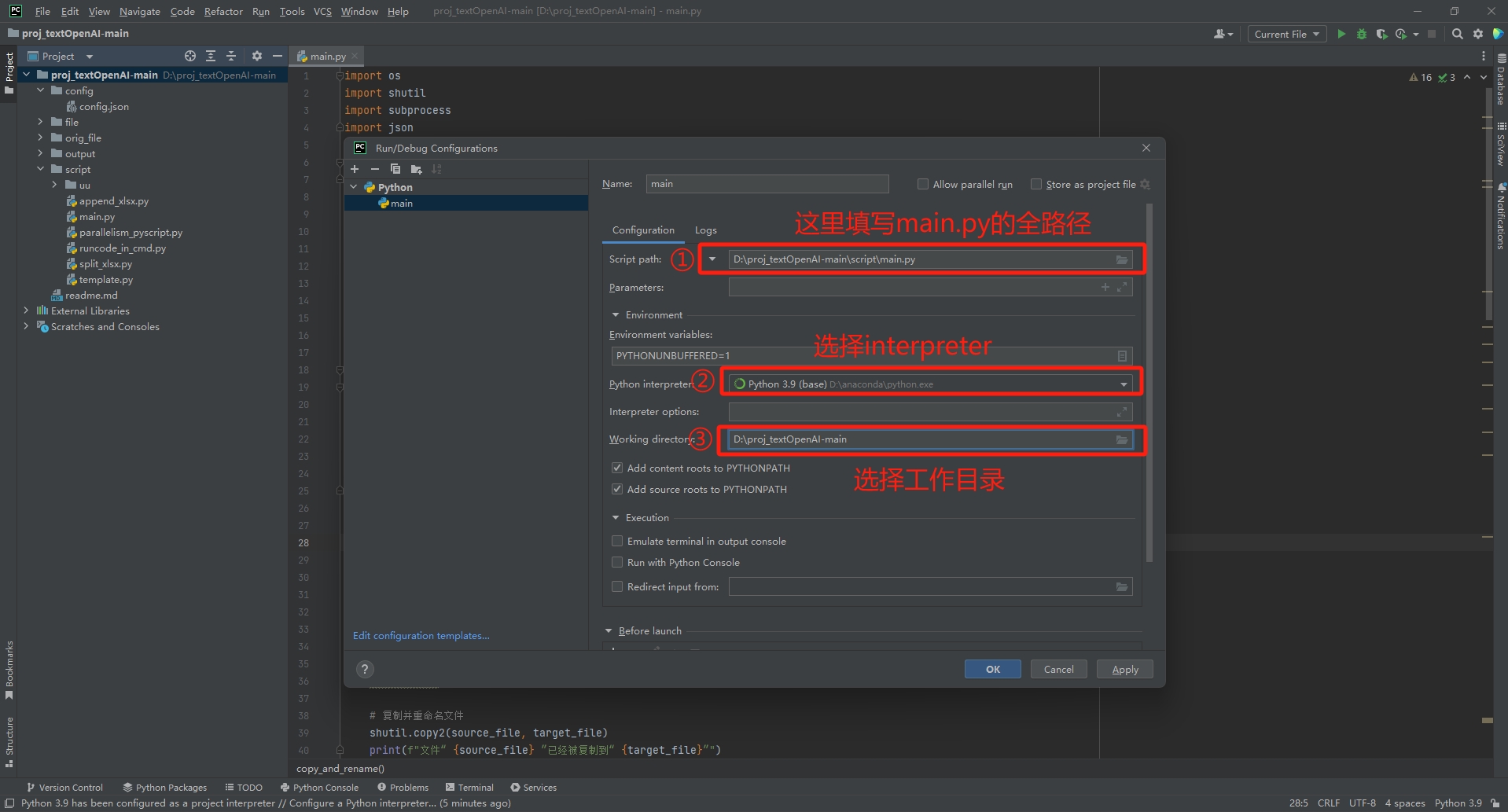
至此,整个项目就已经部署好且已经完成运行。