如何在stata中实现交错did
1.数据生成
(1)数据生成过程
- 我将随机生成一个数据来模拟staggered-DID,即设定了50个unit,其中第
1/3/5/7/9/11/13/15/17/19个unit是实验组,剩下的40个unit为对照组。 -
生成一个自然年份
year,从2001-2020年 - 我将随机给treatment group分配一个shock时间,并生成对应的
treatyear变量
| unit | shock year |
|---|---|
| id == 1|3 | 2010 |
| id == 5|7|9 | 2011 |
| id == 11|13 | 2012 |
| id == 15 | 2013 |
| id == 17|19 | 2014 |
-
根据
treat、year以及treatyear等变量:-
生成相对时间
ty,用以衡量各年是shock发生前或后的第几年 - 生成
post变量,用于反映shock是否已经发生 - 生成
did项
-
-
最后,利用随机数,生成outcome变量,
lnv
以下是实现过程,注意运行一下程序须保证stata安装egenmore包
(2)数据生成代码
**# 1.生成数据
clear
cap snapshot erase _all
set obs 1000
egen id = repeat() ,v(1/50)
sort id
egen year = repeat(), v(2001/2020)
gen treat = mod(id,2) & id <= 20
gen treatyear = 2010 if id <= 3
replace treatyear = 2011 if id > 3 & id <= 9
replace treatyear = 2012 if id > 9 & id <= 13
replace treatyear = 2013 if id > 13 & id <= 15
replace treatyear = 2014 if id > 15 & id <= 19
gen ty = year - treatyear
gen post = (ty >= 0)
gen did = treat * post
gen lnv = log(rnormal() +10 + sqrt( 1 + rnormal() ^ 2))
replace lnv = lnv + log(uniform()+1) if treat == 1 & post == 1
(3)数据生成结果
2.数据预加工
(1)加工步骤
在得到数据后,须先对数据进行一定处理,才可进行staggered-DID估计,主要有以下几步:
- 生成各期的虚拟变量,例如:
- 对于事前第1期($k=-1$),需要生成一个虚拟变量
f_1,当ty=-1时,f_1等于1,否则f_1等于0 - 对于事后第2期($k=2$),需要生成一个虚拟变量
l_2,当ty=2时,l_2等于1,否则l_2等于0
- 对于事前第1期($k=-1$),需要生成一个虚拟变量
- 设定基期,另基期的时间虚拟变量等于0,一般选择事前1期($ty=-1$),或者发生当期($ty=0$),此时将
f_1变量或者l_0变量替换成0 - 如使用交互加权法,还需生成never_treat 和 last_cohort虚拟变量:
- never_treat变量即用来识别从来没有发生过shock的unit
- last_cohort变量即用来识别对于每个unit而言,当期是否为被处理的最后一期
(2)数据预加工代码
**# 2.处理数据
gen _ty = abs(ty) // 生成时间period变量
tab _ty if ty < 0 ,gen(f_) // 生成事前period Dummy
su _ty if ty < 0
global dim = r(max)
forv i = 1/$dim{
replace f_`i' = 0 if f_`i' == .
}
tab _ty if ty > 0 ,gen(l_) // 生成事后period Dummy
su _ty if ty > 0
global dim = r(max)
forv i = 1/$dim{
replace l_`i' = 0 if l_`i' == .
}
gen l_0 = ty == 0 // 生成当期period Dummy
gen never_treat = treatyear==. // 生成当期never_treat 和 last_cohort
su treatyear
gen last_cohort = treatyear==r(max)
replace f_1 = 0 //将-1期设定为基期
snapshot save, label("did")
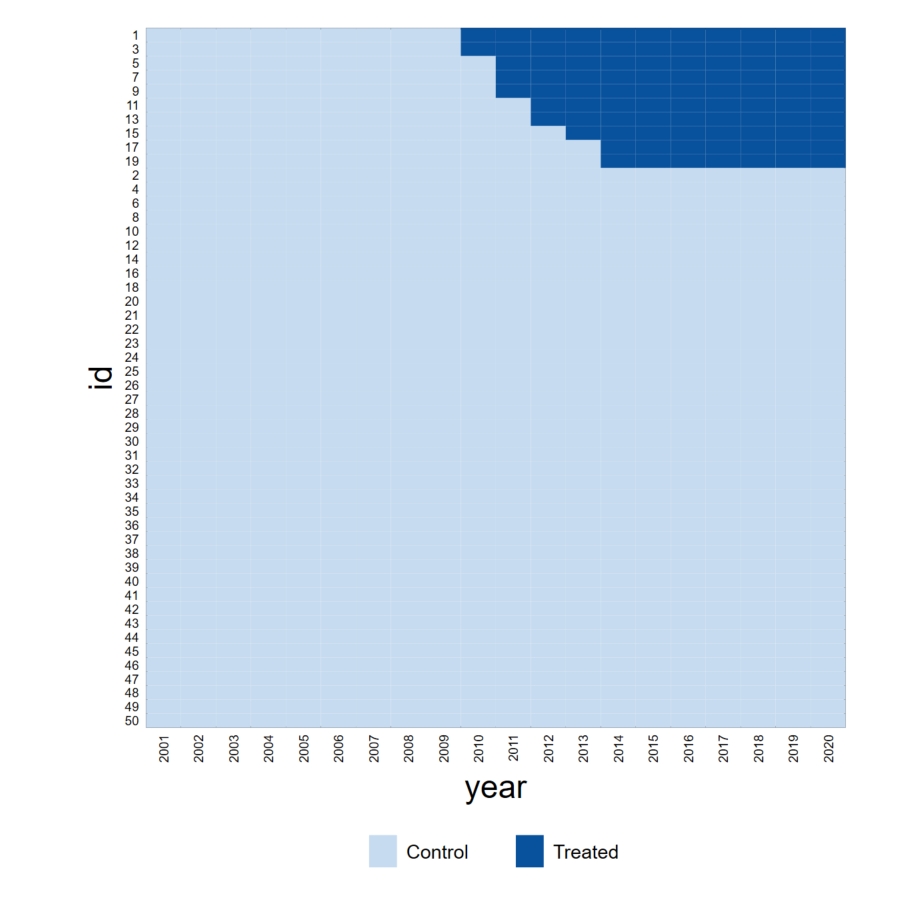
3.查看面板
对处理好的面板进行检查,直观地描绘出不同unit面临的staggered冲击
**# 3.panelview
snapshot restore 1
panelview did ,i(id) t(year) type(treat) bytiming
// panelview lnv did ,i(id) t(year) type(outcome)
4.基准回归
使用双向固定效应模型对DID估计量进行估计。staggered-DID存在负权重问题(异质性处理效应,即早处理组成为了晚处理组的对照组),一般会使用Bacon分解,CSDID,交互加权法,fect等方法来解决。
(1)原理释义
- TWFE:直接估计DID估计量,可能存在负权重问题
- CSDID:将staggered面板拆成若干个2×2的标准DID,对照组即
一直未接收处理的个体(never-treated)或还未接受处理的个体(not-yet- treated)
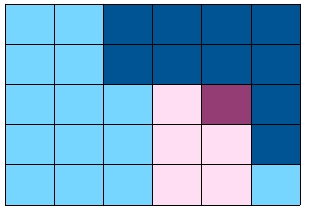
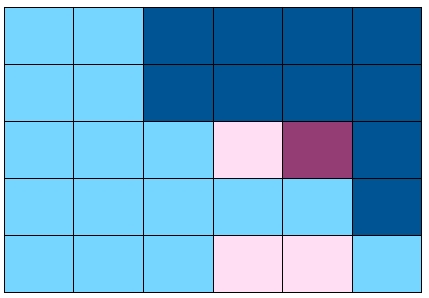
- 交互加权(Interaction Weighted):将staggered面板拆成若干个2×2的标准DID,对照组即
非处理组(never-treated)或者最晚处理组(last-treated)。
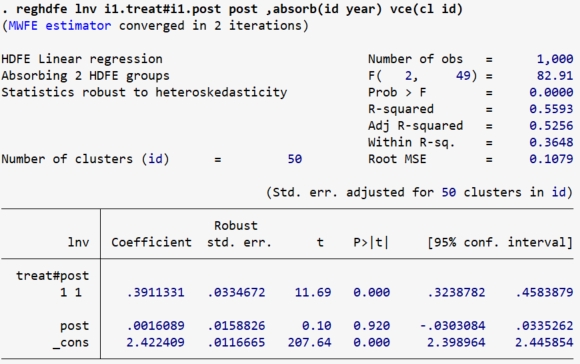
(2)基于TWFE的基准回归
// 基于TWFE(two-way fixed effect)
snapshot restore 1
reghdfe lnv i1.treat#i1.post post ,absorb(id year) vce(cl id)
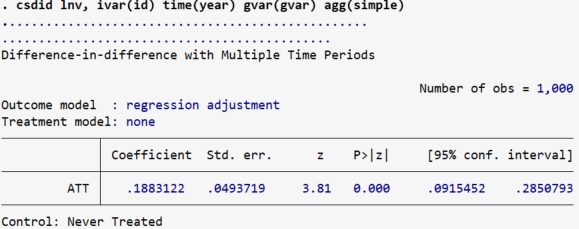
(3)基于CSDID的基准回归
snapshot restore 1
gen gvar = cond(treatyear==., 0, treatyear)
csdid lnv, ivar(id) time(year) gvar(gvar) agg(simple)
5.平行趋势检验
DID需满足平行趋势假设,本文将分别基于TWFE\CSDID\Interact weighted方法进行检验,须安装event_plot命令
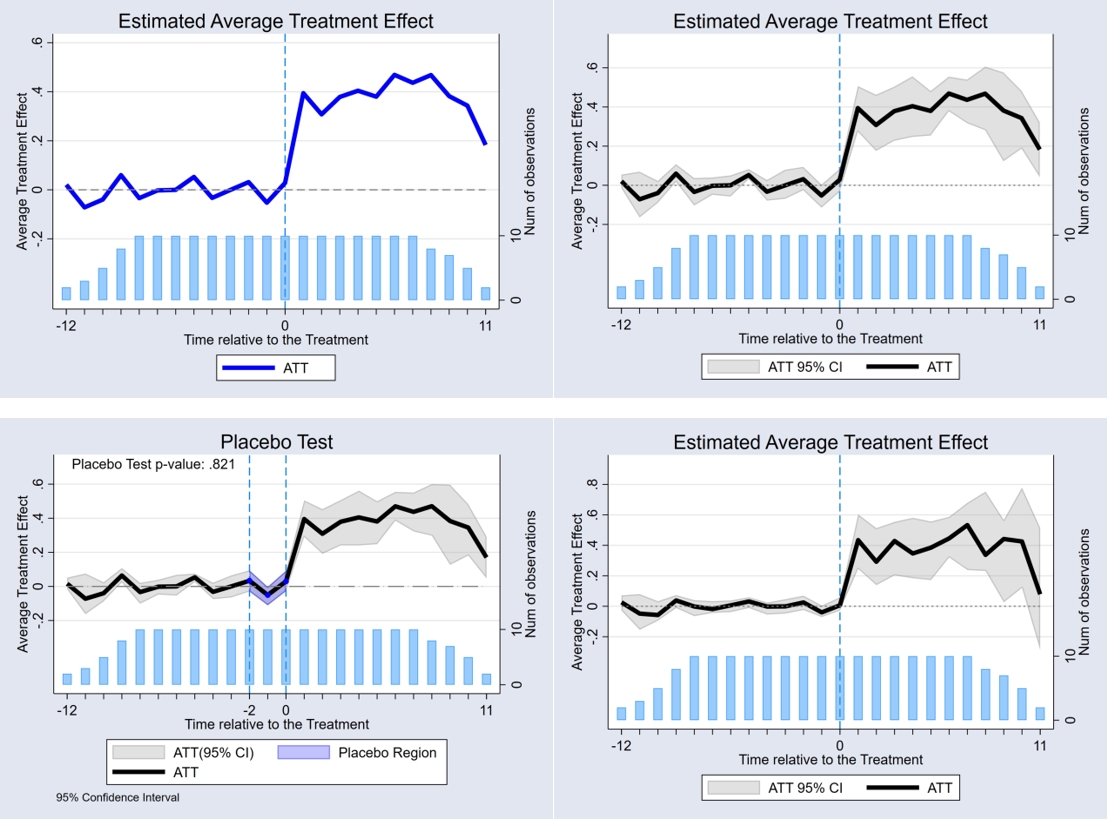
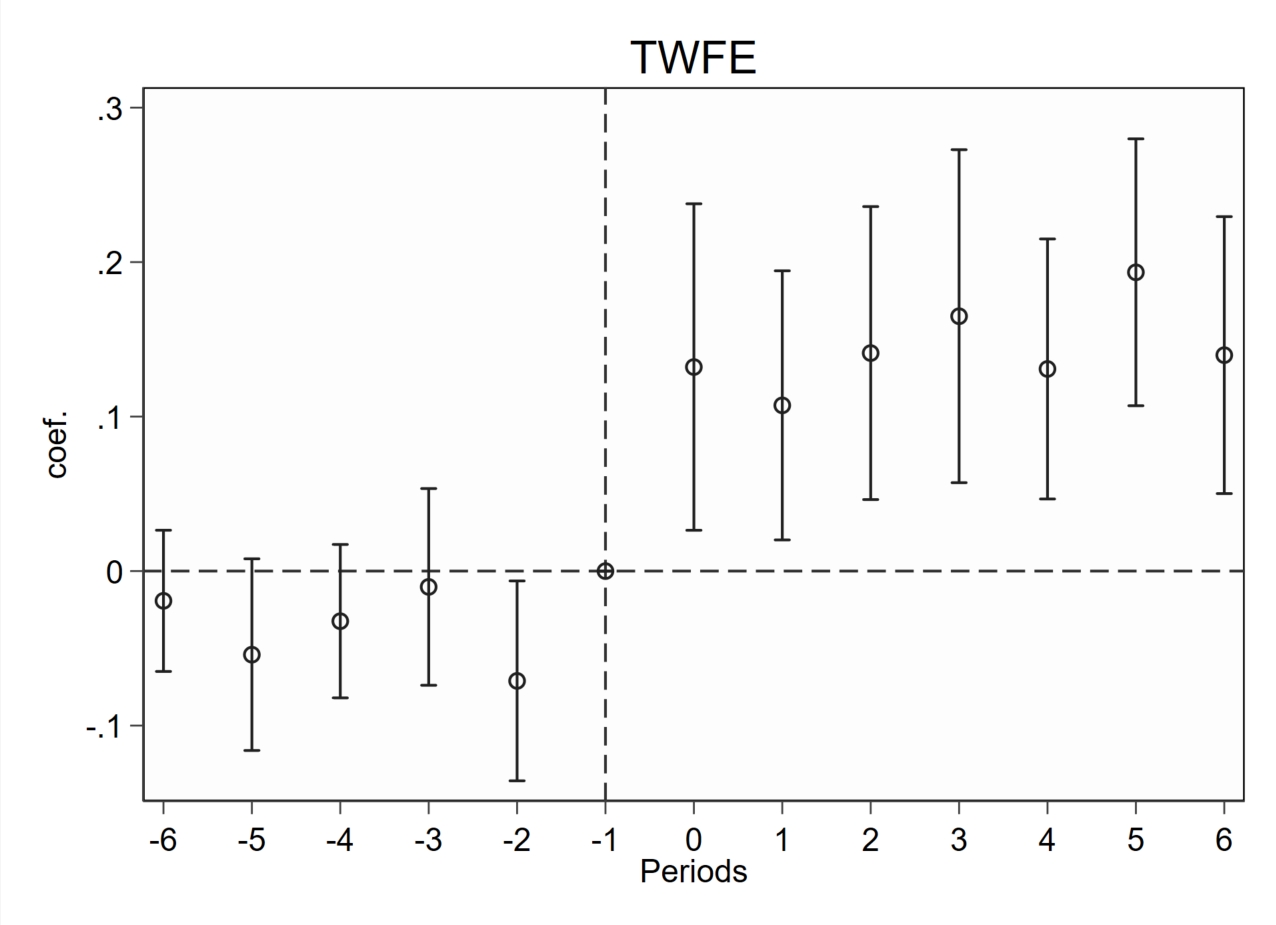
(1)基于TWFE
snapshot restore 1
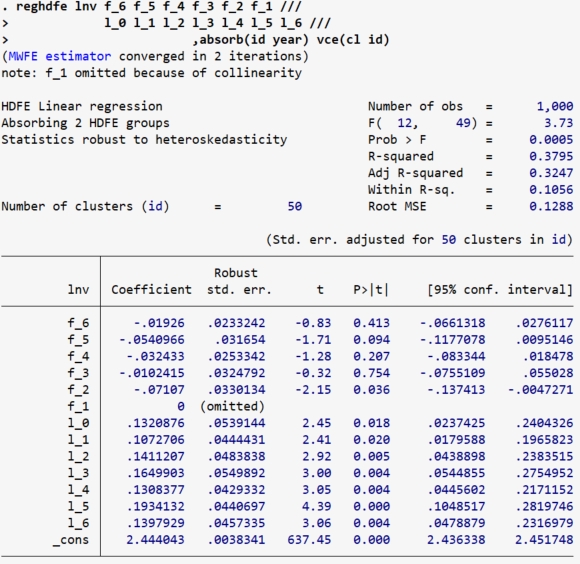
reghdfe lnv f_6 f_5 f_4 f_3 f_2 f_1 ///
l_0 l_1 l_2 l_3 l_4 l_5 l_6 ///
,absorb(id year) vce(cl id)
// 绘制图象
event_plot e(b)#e(V), plottype(scatter) ///
stub_lag(l_#) stub_lead(f_#) together ///
graph_opt(name(TWFE, replace) title("TWFE") ///
xtitle("Periods") ///
ytitle("coef.") ///
xlabel(-6(1)6) ylabel(,nogrid) ///
yline(0, lp(dash) ) xline(-1, lp(dash) ))
(2)基于CSDID
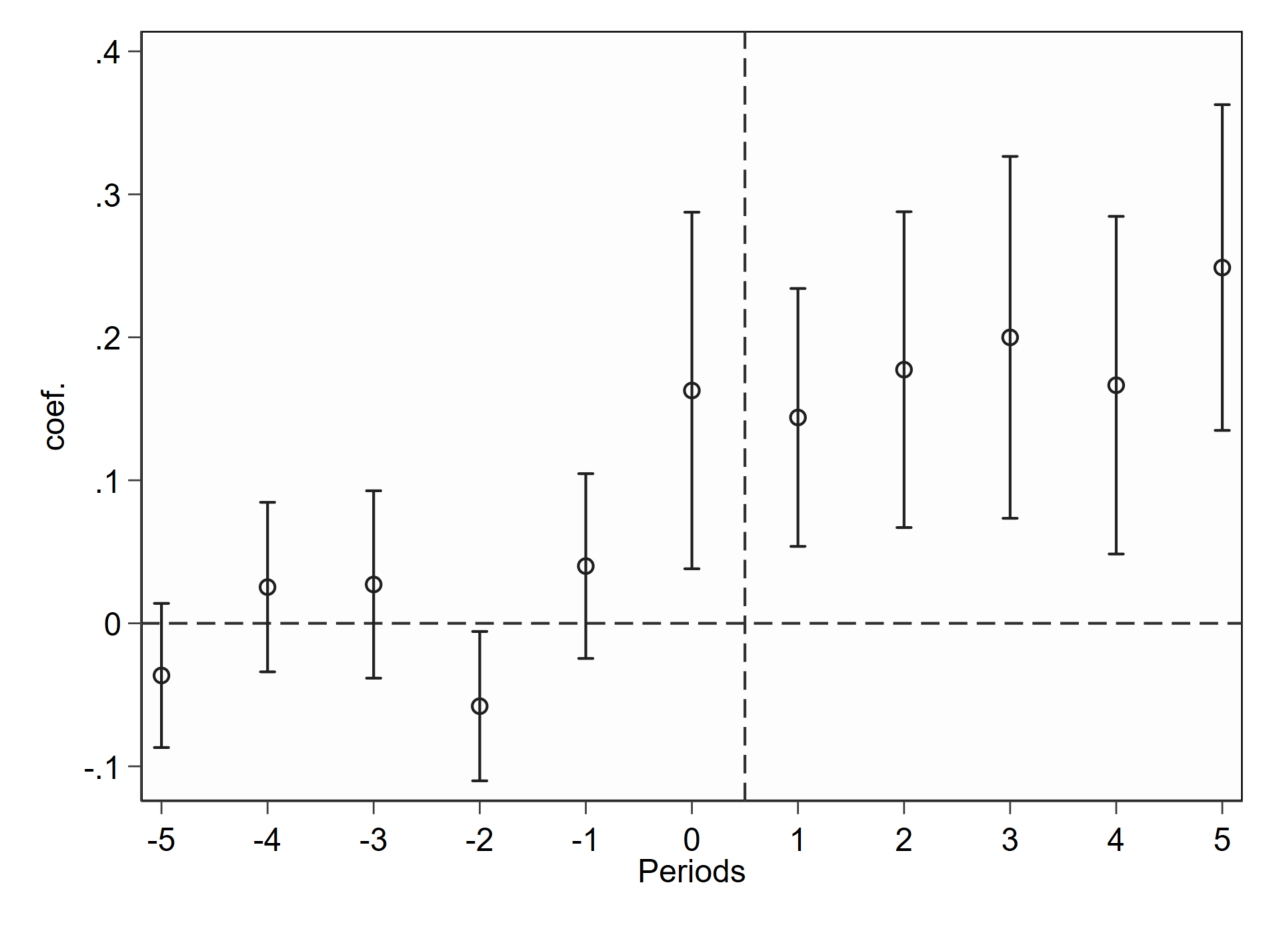
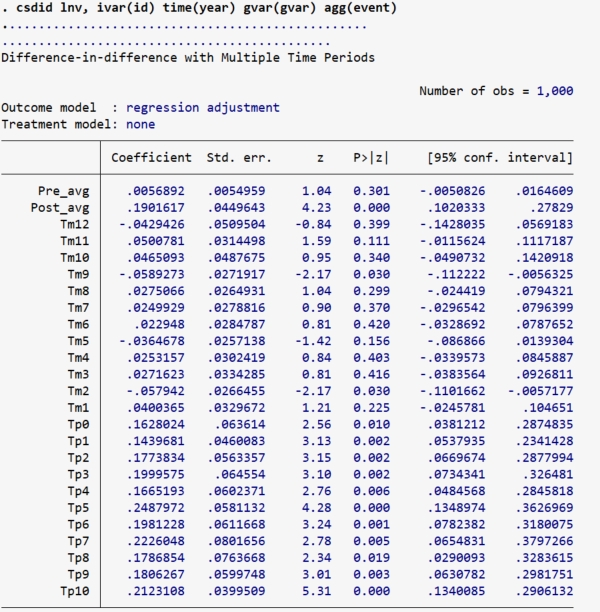
snapshot restore 1
gen gvar = cond(treatyear==., 0, treatyear)
csdid lnv, ivar(id) time(year) gvar(gvar) agg(event)
estat event, window(-5 5) estore(cs)
event_plot cs, plottype(scatter) ///
stub_lag(Tp#) stub_lead(Tm#) together ///
graph_opt(name(CSDID, replace) ///
xtitle("Periods") ytitle("coef.") ///
xlabel(-5(1)5) ylabel(,nogrid) ///
yline(0, lp(dash)) xline(0.5, lp(dash)))
(3)基于交互加权法
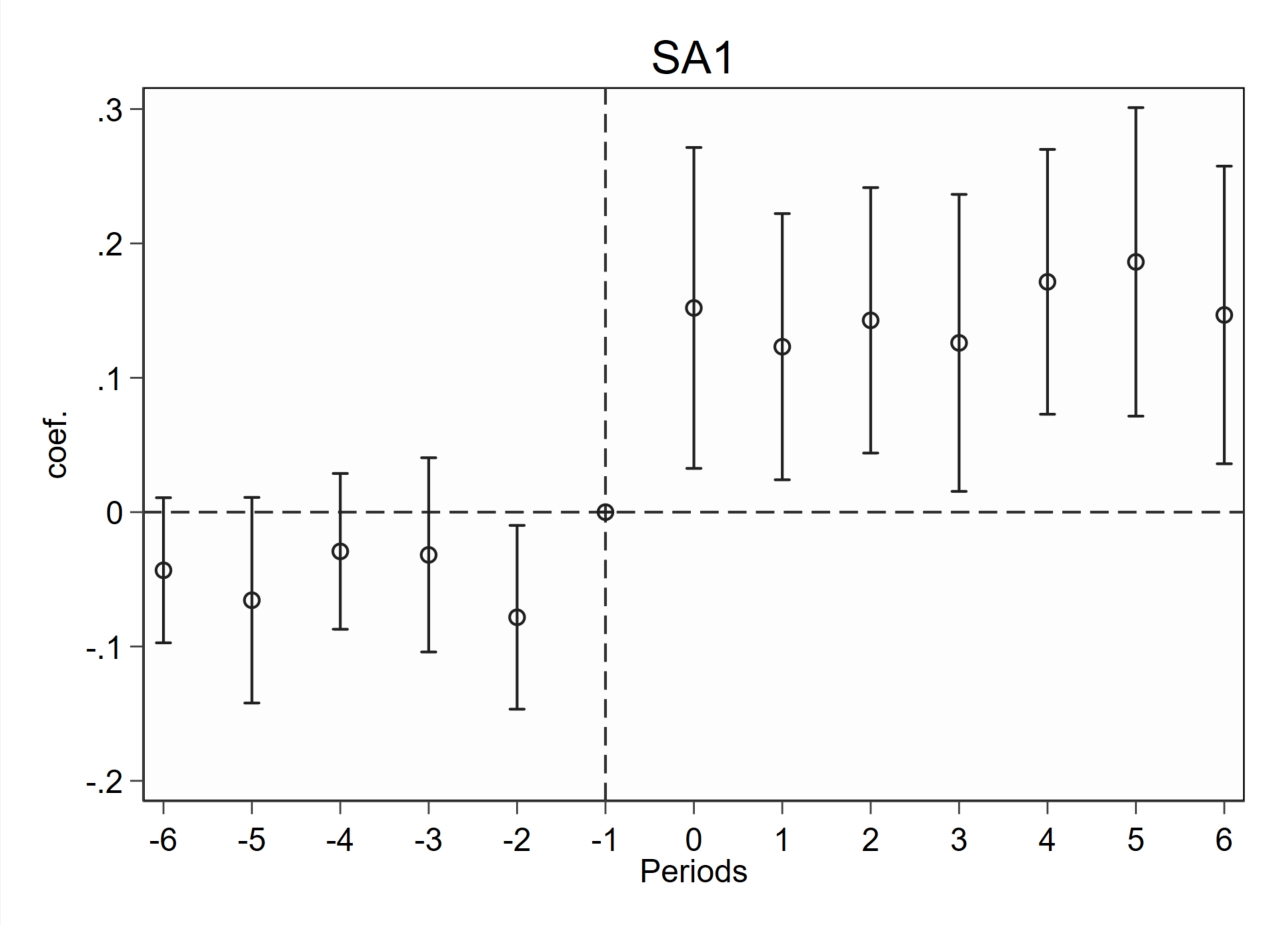
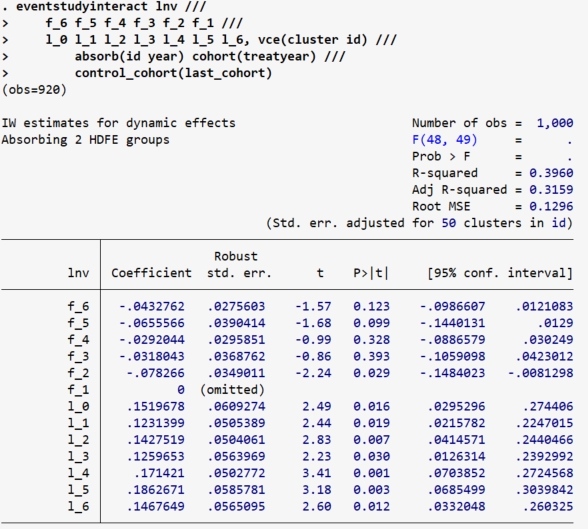
a.last-cohort作为控制组
snapshot restore 1
*使用last_cohort作为控制组
eventstudyinteract lnv ///
f_6 f_5 f_4 f_3 f_2 f_1 ///
l_0 l_1 l_2 l_3 l_4 l_5 l_6, vce(cluster id) ///
absorb(id year) cohort(treatyear) ///
control_cohort(last_cohort)
*绘制图象
event_plot e(b_iw)#e(V_iw), plottype(scatter) ///
stub_lag(l_#) stub_lead(f_#) together ///
graph_opt(name(SA1, replace) title("SA1") ///
xtitle("Periods") ytitle("coef.") ///
xlabel(-6(1)6) ylabel(,nogrid) ///
yline(0, lp(dash)) xline(-1, lp(dash)))
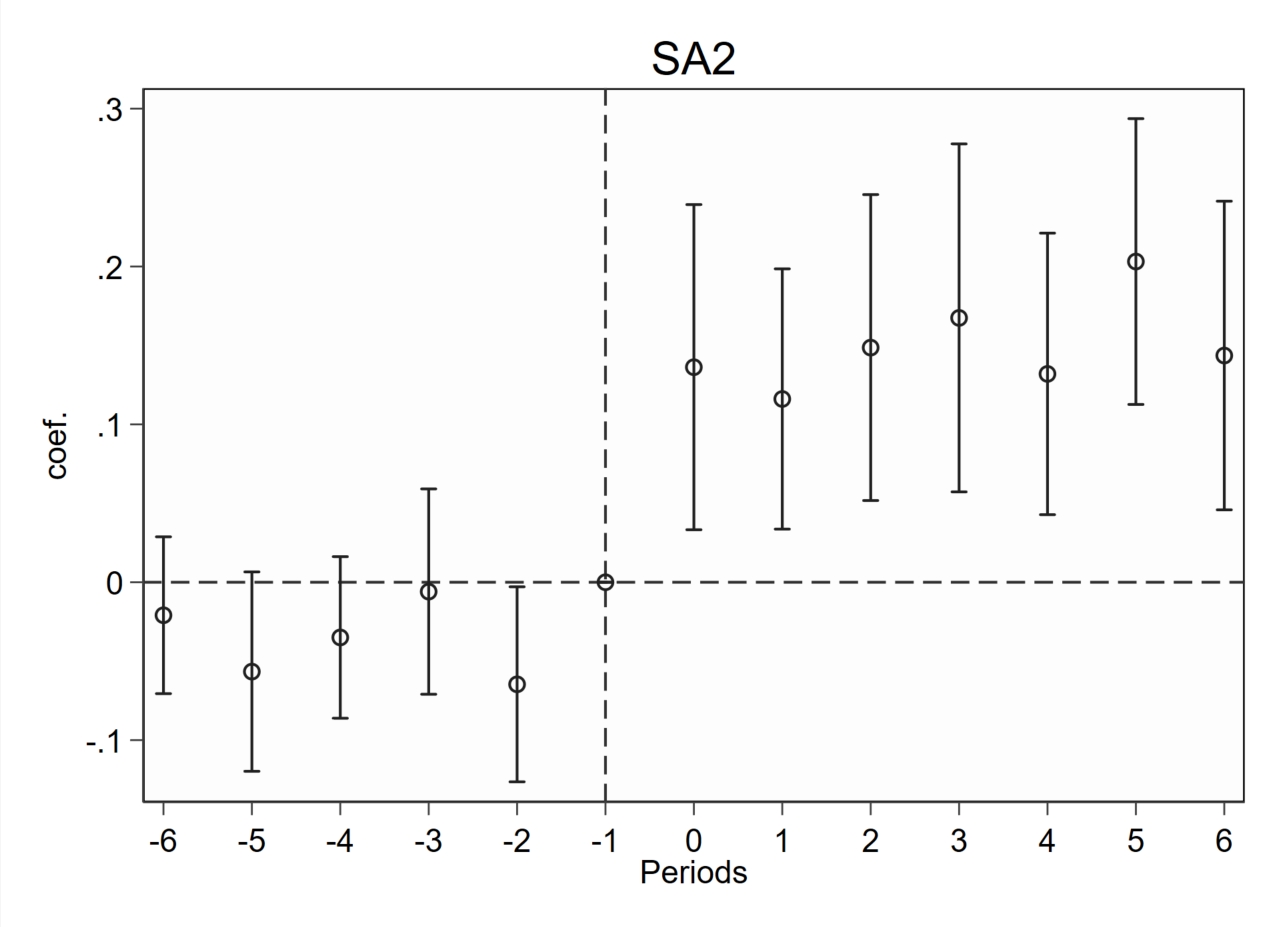
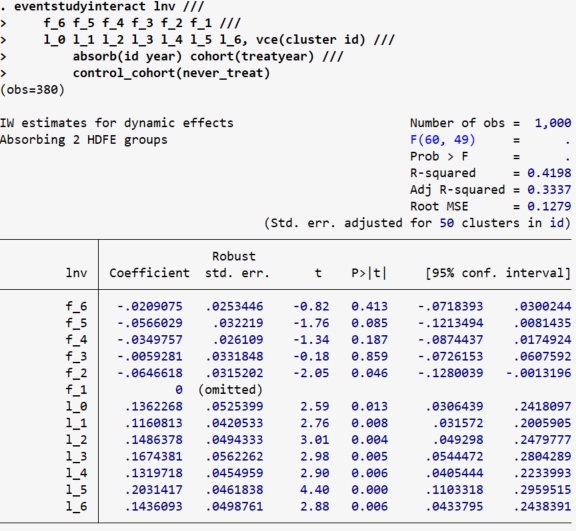
b.never-treated作为控制组
snapshot restore 1
*使用never_treated作为控制组
eventstudyinteract lnv ///
f_6 f_5 f_4 f_3 f_2 f_1 ///
l_0 l_1 l_2 l_3 l_4 l_5 l_6, vce(cluster id) ///
absorb(id year) cohort(treatyear) ///
control_cohort(never_treat)
*再次绘制图象
event_plot e(b_iw)#e(V_iw), plottype(scatter) ///
stub_lag(l_#) stub_lead(f_#) together ///
graph_opt(name(SA2, replace) title("SA2") ///
xtitle("Periods") ytitle("coef.") ///
xlabel(-6(1)6) ylabel(,nogrid) ///
yline(0, lp(dash)) xline(-1, lp(dash)))
(4)fect反事实
fect lnv, treat(did) unit(id) time(year) method("fe") r(2)
fect lnv, treat(did) unit(id) time(year) method("fe") r(2) se nboots(200)
fect lnv, treat(did) unit(id) time(year) method("ife") r(2) se nboots(200)
fect lnv, treat(did) unit(id) time(year) se method("fe") r(2) placeboTest